常用的sql语句
1、查询最近30天(这个可以自行设置灵活变化)
SELECT DATE_ADD(CURDATE(), INTERVAL(CAST(-help_topic_id AS SIGNED INTEGER))DAY) DAY FROM mysql.help_topic WHERE help_topic_id < 30 ORDER BY help_topic_id2、组织机构的递归树
SELECT
ID.LEVEL, DATA.*
FROM
(
SELECT
@ids AS _ids,
( SELECT @ids := GROUP_CONCAT( ORGNA_ID ) FROM jcy_vscloud.ENT_ORGANIZATION WHERE FIND_IN_SET( PORGNA_ID, @ids ) ) AS cids,
@l := @l + 1 AS LEVEL
FROM
jcy_vscloud.ENT_ORGANIZATION,
( SELECT @ids := '0', @l := 0 ) b
WHERE
@ids IS NOT NULL
) ID,
jcy_vscloud.ENT_ORGANIZATION DATA
WHERE
FIND_IN_SET( DATA.ORGNA_ID, ID._ids )
ORDER BY
LEVEL,
ORGNA_ID3、删除数据表的重复数据只保留一条
DELETE
FROM
t_zc_fzdyxx_copy1
WHERE
(zjd,csq,xm,sfzh,sjmc,sjrq) IN (
SELECT
a.zjd,a.csq,a.xm,a.sfzh,a.sjmc,a.sjrq
FROM
(
SELECT
zjd,csq,xm,sfzh,sjmc,sjrq
FROM
t_zc_fzdyxx_copy1
GROUP BY
zjd,csq,xm,sfzh,sjmc,sjrq
HAVING
count(1) > 1
) a
)
AND cjsj NOT IN (
SELECT
dt.mincjsj
FROM
(
SELECT
min(cjsj) AS mincjsj
FROM
t_zc_fzdyxx_copy1
GROUP BY
zjd,csq,xm,sfzh,sjmc,sjrq
HAVING
count(1) > 1
) dt
)4、MySQL 批量修改库、表、列的排序规则
1、表字段修复:
SELECT TABLE_SCHEMA '数据库',TABLE_NAME '表',COLUMN_NAME '字段',CHARACTER_SET_NAME '原字符集',COLLATION_NAME '原排序规则',CONCAT('ALTER TABLE ', TABLE_SCHEMA,'.',TABLE_NAME, ' MODIFY COLUMN ','`',COLUMN_NAME,'`',' ',COLUMN_TYPE,' CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;') '修正SQL'
FROM information_schema.`COLUMNS`
WHERE TABLE_SCHEMA RLIKE 'gyhlw' AND CHARACTER_SET_NAME is not null;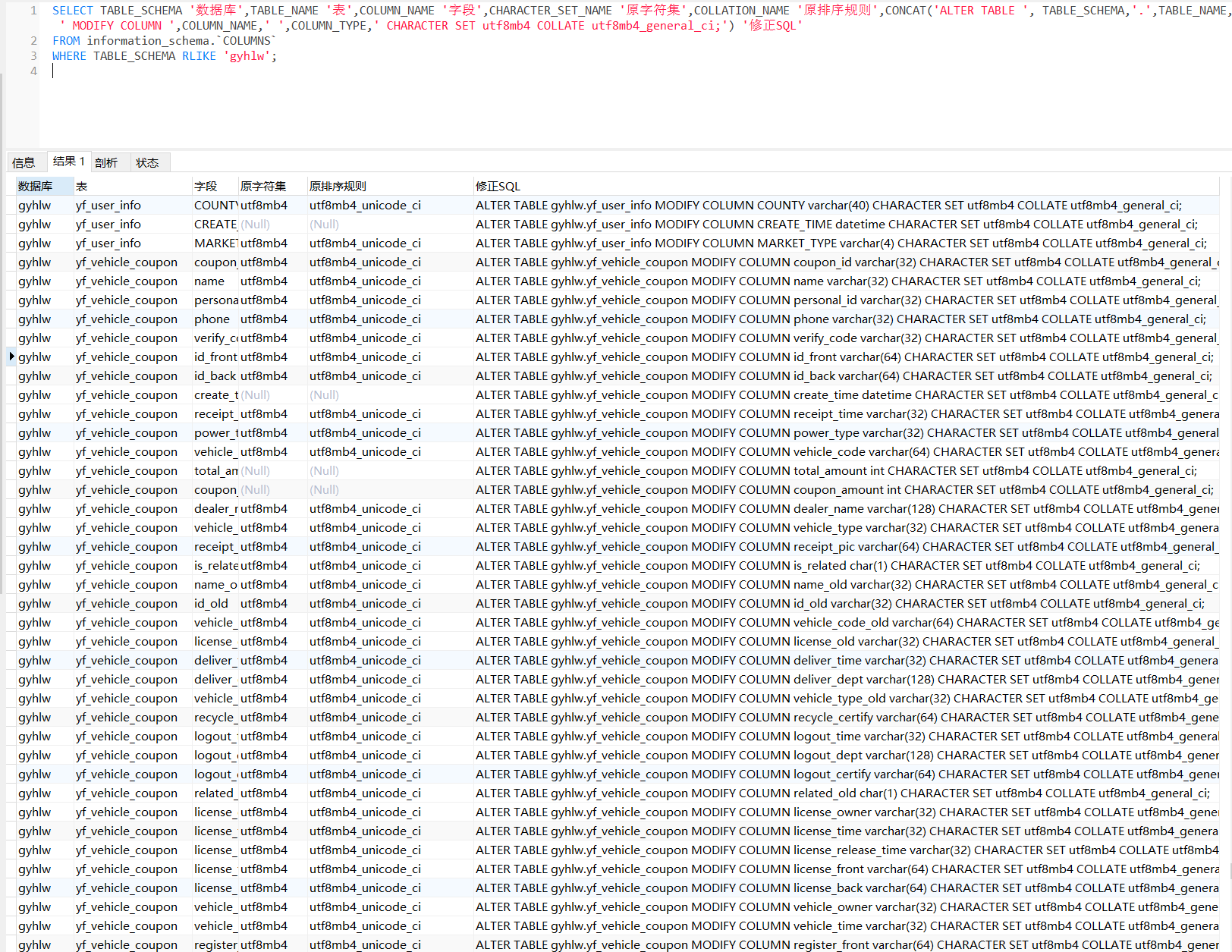
最后把把修正的SQL复制出来运行,字段标准就修复了。
2、表修复:
SELECT TABLE_SCHEMA '数据库',TABLE_NAME '表',TABLE_COLLATION '原排序规则',CONCAT('ALTER TABLE ',TABLE_SCHEMA,'.', TABLE_NAME, ' COLLATE=utf8mb4_general_ci;') '修正SQL'
FROM information_schema.`TABLES`
WHERE TABLE_SCHEMA RLIKE 'gyhlw';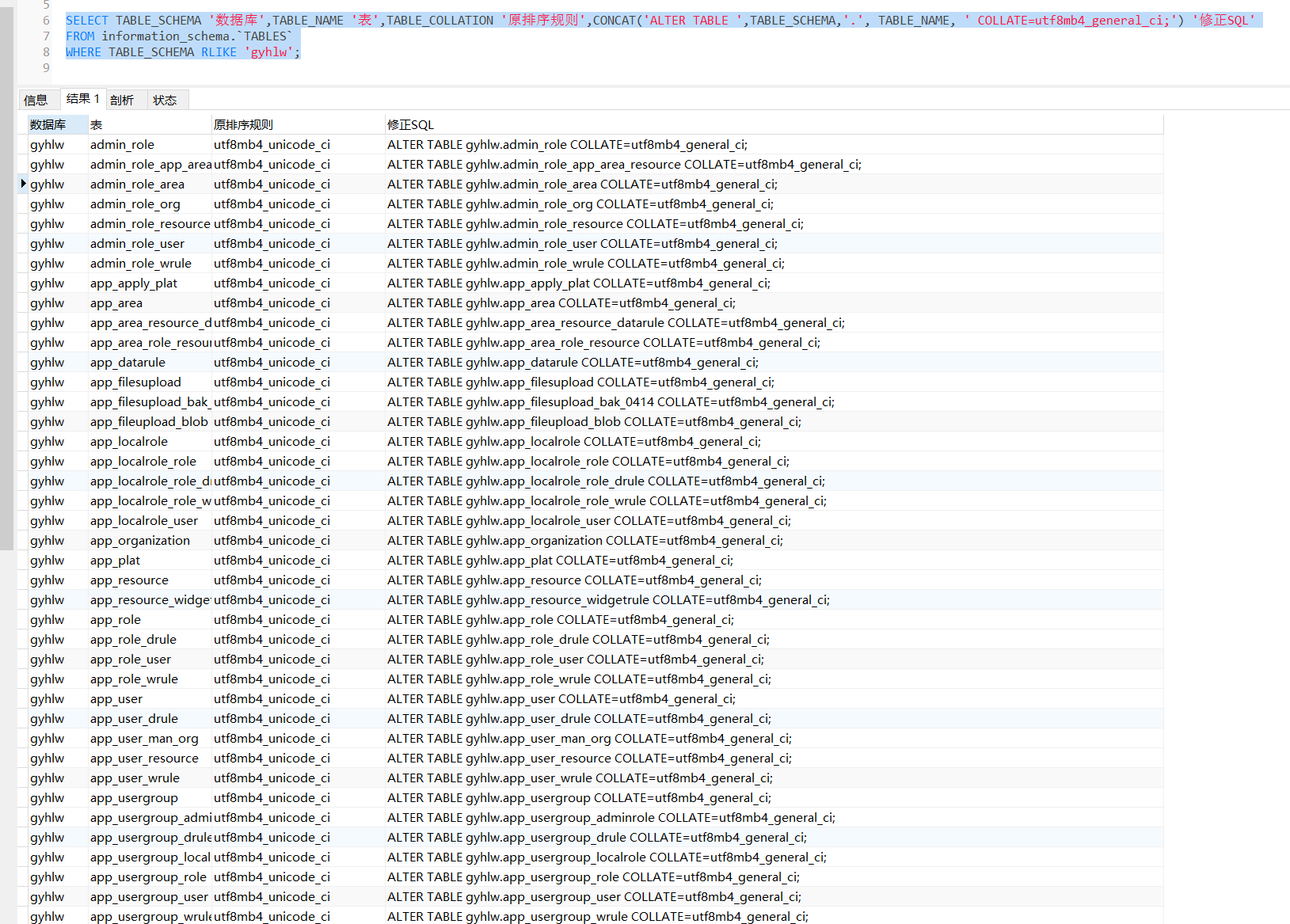
5、MySQL 根据条件查询数据库所有的表名,并用逗号连接
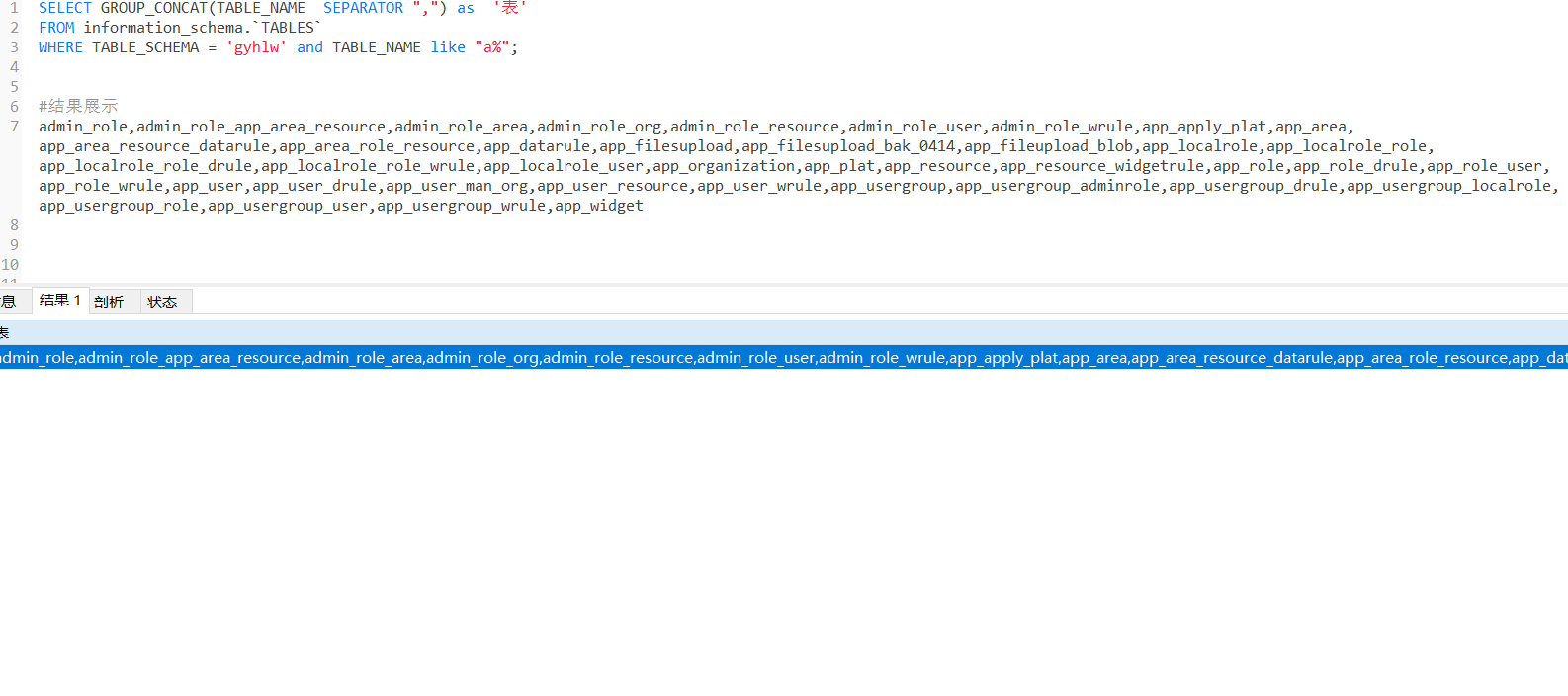
SELECT GROUP_CONCAT(TABLE_NAME SEPARATOR ",") as '表'
FROM information_schema.`TABLES`
WHERE TABLE_SCHEMA = 'gyhlw' and TABLE_NAME like "a%";
#结果展示
admin_role,admin_role_app_area_resource,admin_role_area,admin_role_org,admin_role_resource,admin_role_user,admin_role_wrule,app_apply_plat,app_area,app_area_resource_datarule,app_area_role_resource,app_datarule,app_filesupload,app_filesupload_bak_0414,app_fileupload_blob,app_localrole,app_localrole_role,app_localrole_role_drule,app_localrole_role_wrule,app_localrole_user,app_organization,app_plat,app_resource,app_resource_widgetrule,app_role,app_role_drule,app_role_user,app_role_wrule,app_user,app_user_drule,app_user_man_org,app_user_resource,app_user_wrule,app_usergroup,app_usergroup_adminrole,app_usergroup_drule,app_usergroup_localrole,app_usergroup_role,app_usergroup_user,app_usergroup_wrule,app_widget
6.mysql中with as的用法
在mysql中,“with as”也叫子查询,用于定义一个sql片段,且该片段会被整个sql语句反复使用很多次,这个sql片段就相当于是一个公用临时表,语法为“with tmp as (查询语句)”。

WITH AS短语,也叫做子查询部分(subquery factoring),可以定义一个SQL片断,该SQL片断会被整个SQL语句用到。可以使SQL语句的可读性更高,也可以在UNION ALL的不同部分,作为提供数据的部分。
对于UNION ALL,使用WITH AS定义了一个UNION ALL语句,当该片断被调用2次以上,优化器会自动将该WITH AS短语所获取的数据放入一个Temp表中。而提示meterialize则是强制将WITH AS短语的数据放入一个全局临时表中。很多查询通过该方式都可以提高速度。
因with as 子查询仅执行一次,将结果存储在用户临时表中,提高查询性能,所以适合多次引用的场景,如:复杂的报表统计,分页查询,且需要拿到sum、count、avg这类结果作为筛选条件,对查询出的结果进行二次处理!
特别对于union all比较有用。因为union all的每个部分可能相同,但是如果每个部分都去执行一遍的话,则成本太高
常用语法
–针对一个别名
with tmp as (select * from tb_name)–针对多个别名
with
tmp as (select * from tb_name),
tmp2 as (select * from tb_name2),
tmp3 as (select * from tb_name3),
…–相当于建了e、d临时表
with
e as (select * from scott.emp),
d as (select * from scott.dept)
select * from e, d where e.deptno = d.deptno;其实就是把一大堆重复用到的sql语句放在with as里面,取一个别名,后面的查询就可以用它,这样对于大批量的sql语句起到一个优化的作用,而且清楚明了。
示例代码
WITH SS AS (SELECT
DISTRICT_NAME,
ORDER_INDEX,
gld.LD_SFZH,
sam.card_nocy,
test.card_no1
FROM
zdrq_xzqh A
LEFT JOIN (SELECT GLD.* FROM yqfk_ryxx gld
LEFT JOIN yqfk_ryxx_zy zy on gld.id= zy.pid
WHERE zy.GLD_JSSJ IS NOT NULL
AND zy.GLD_GLJSSJ IS NULL ) GLD ON A.DISTRICT_code = gld.LD_XZQH
LEFT JOIN hs_sample_data_dongying_view sam ON gld.LD_SFZH = sam.card_nocy
AND sam.create_time >#{startTime}
LEFT JOIN hs_data_dongying test ON gld.LD_SFZH = test.card_no1
AND test.test_time >#{startTime}
WHERE A.DISTRICT_LEVEL='SYS1704')
SELECT 'xxx' AS DISTRICT_NAME, '0' AS ORDER_INDEX,COUNT(DISTINCT LD_SFZH) AS XGLRS,COUNT(DISTINCT CARD_NOCY) AS CYRS,COUNT(DISTINCT CARD_NO1) AS WCJCRS
FROM SS
UNION ALL
SELECT DISTRICT_NAME,ORDER_INDEX,COUNT(DISTINCT LD_SFZH) AS GLRS,COUNT(DISTINCT CARD_NOCY) AS CYRS,COUNT(DISTINCT CARD_NO1) AS WCJCRS
FROM SS
GROUP BY DISTRICT_NAME,ORDER_INDEX
ORDER BY ORDER_INDEX


